Affiliations d'un auteur dans HAL - OpenRefine
Dans le cadre d'un projet de nettoyage de données dans HAL, il nous a été demandé d'identifier pour un auteur une liste de ses publications sous la forme suivante :
| Document Id | Structure | Structure Id | Année de publication |
|---|
Ce billet présente une solution basée sur OpenRefine, LibreOffice calc et les API de HAL. Il existe sûrement des solutions plus simples, mais celle-ci offre l'avantage d'être facilement transposable. Une option plus simple passerait peut-être par une meilleure connaissance de l'API HAL, n'hésitez pas à m'indiquer si je suis passé à côté de quelque chose.
Mise à jour du 12 avril 2019 : en réponse à un tweet annonçant ce billet, Marlène Delhaye suggère d'utiliser OcidHal qui semble en effet répondre à l'objet de ce billet puisqu'il permet d'identifier toutes les publications liées à une combinaison nom/prénom. L'explication de ce billet reste intéressante pour une utilisation de l'API HAL dans OpenRefine mais pour l'objet final du billet initial OcidHal semble en effet une solution plus directe.
Récupération des données
La documentation search de l'API HAL permet de trouver la requête à utiliser pour récupérer les informations de structure ( structPrimaryHasAuthId_fs ) associées à un auteur sur la base de son authId. Cet identifiant est un identifiant numérique que l'on trouve sur la fiche Aurehal d'un auteur (363823 pour moi par exemple) :
https://api.archives-ouvertes.fr/search/?q=authId_i:363823&wt=xml&fl=halId_s,structPrimaryHasAuthId_fs,producedDate_tdate&sort=producedDate_tdate%20asc&rows=100Si l'auteur a plusieurs entrées AureHAL, on pourra les récupérer en une fois via une recherche OR :
https://api.archives-ouvertes.fr/search/?q=(authId_i:363823%20OR%20authId_i:363823)&wt=xml&fl=structPrimaryHasAuthId_fs,halId_s,producedDate_tdate&sort=producedDate_tdate%20asc&rows=100Notes sur cette url :
- penser à mettre à jour rows= à la fin de l'URL si vous avez plus de 100 résultats. La documentation indique que l'on peut aller jusqu'à 10 000.
- les champs demandés sont passés en paramètres fl=. Il existe des dizaines de champs disponibles. Pour affiner votre demande, vous pouvez utiliser des * dans votre requêtes. En mettant *date* ou *Date* vous pourrez par exemple récupérer tous les champs contenant le terme date (attention, paramètre sensible à la casse) et ainsi voir lequel convient pour construire l'URL finale : exemple pour identifier la bonne date.
- le paramètre sort nous permet d'avoir une liste déjà triée, qui sera plus facile à traiter par la suite pour vérifier l'historique des affiliations.
Le document résultant, en XML, peut alors être enregistré au format XML sur le disque dur.
Préparation du fichier dans OpenRefine
Le fichier XML récupéré précédemment va pouvoir être ouvert dans OpenRefine. Lorsque l'on ouvre un fichier XML dans OpenRefine, il va nous demander de choisir la racine correspondant à un enregistrement en survolant le fichier. Dans notre exemple c'est la balise <doc> que l'on peut sélectionner sur n'importe laquelle des entrées :
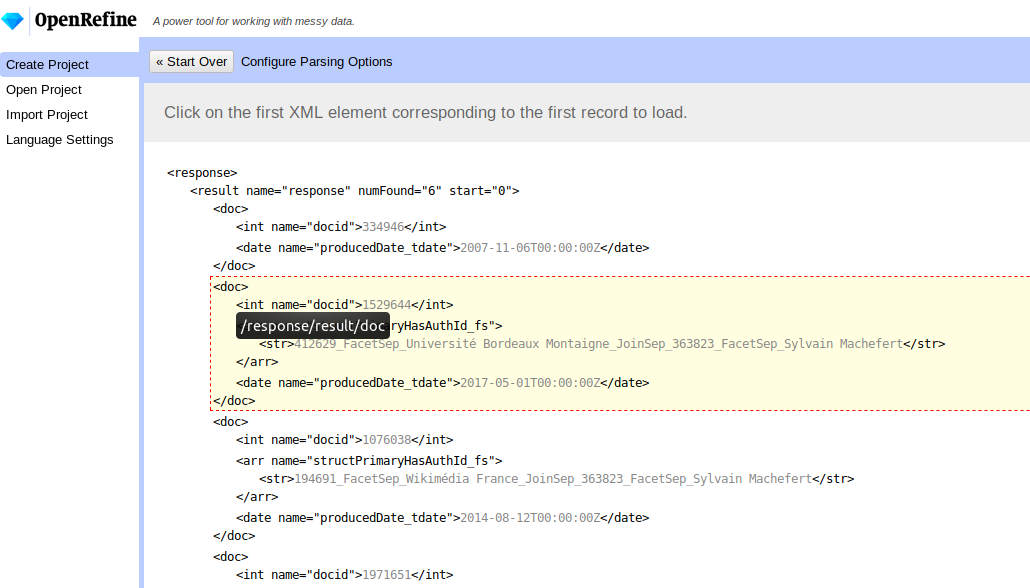
Si tout se passe correctement, la prévisulatisation devrait ressembler à cela :

On choisit create project et l'on va pouvoir commencer à traiter les données. La première chose à faire, si ce n'est pas le cas (HAL envoie les données dans un ordre qui semble être aléatoire) est d'envoyer la colonne contenant l'identifiant de notice tout à gauche (bouton en haut de colonne > edit column > move to beginning). Cette valeur sera utilisée pour regrouper les lignes multiples correspondant au même enregistrement en "record" au sens OpenRefine. Cette fonction nous sera utile pour gérer les multi-affiliations d'un auteur.
Pour y voir plus clair on peut commencer par supprimer (edit column > remove this column) les colonnes suivantes : doc - str - name, doc - arr - name et doc - date - name. C'est optionnel mais cela nous donne un fichier plus net.
On va ensuite travailler sur la colonne des affiliations pour la séparer en plusieurs colonnes plus lisibles via l'opération "Edit Column > Split into several columns". On effectue deux fois l'opération : une première fois pour le séparateur _FacetSep_ (décocher "Guess cell type" dans les options de la popup, pas forcément utile et peut générer des choses bizarres). On obtient alors une colonne pour l'identifiant de la structure, une qui reste à nettoyer et une dernière avec le nom de l'auteur. On va à nouveau "splitter" la colonne qui reste à nettoyer, cette fois sur le séparateur _JoinSep_. On obtient alors au final dans notre document les colonnes suivantes :
- identifiant du document dans HAL
- identifiant de la structure
- libellé de la structure
- identifiant du chercheur
- nom du chercheur
- date de publication
Le fichier que j'ai à ce moment là est le suivant (en rouge l'illustration du principe des enregistrements regroupés en fonction du docId HAL. C'est une publication à deux auteur, on a deux lignes ("row") dans le fichier OpenRefine qui correspondent à un seul enregistrement ("record")
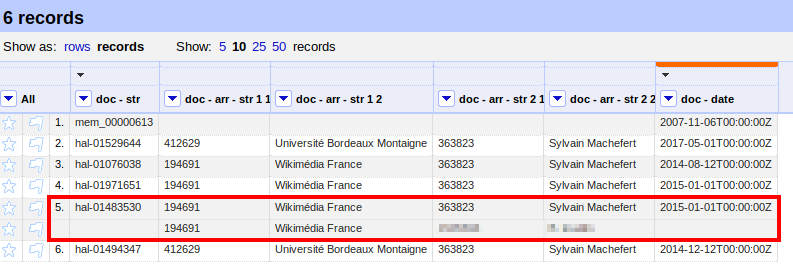
À partir de là j'ai choisi de procéder en deux étapes. On pourrai certainement tout faire dans OpenRefine via des fonctions avancées ou une solution à laquelle je n'ai pas pensée, mais j'ai trouvé plus simple de passer par LibreOffice calc en parallèle. Le problème principal concerne les notices sur lesquelles l'auteur a bien été identifié mais sans affiliation, comme la ligne 1 sur la capture d'écran ci-dessus.
Les deux temps vont donc être les suivants :
- on exporte toutes les notices vers un fichier calc (docId / date de publication)
- on traite les affiliations dans dans OpenRefine (nettoyage de ce qui ne concerne pas l'auteur qui nous intéresse, rassemblement des affiliations multiples ...) avant de l'importer dans LibreOffice Calc pour utiliser des opérations qui nous permettront d'associer à chaque docId la liste des affiliations ou, éventuellement, le fait qu'il n'y a pas d'affiliation.
Export de la liste des notices vers LibreOffice
Pour export seulement les notices, on utilise l'option Export d'OpenRefine > Custom tabular exporter. On sélectionne les colonnes qui nous intéressent (doc - str & doc - date dans le cas qui m'intéresse, mais si on a renommé les colonnes on s'y retrouvera mieux). Penser à décocher l'option "Output empty rows (ie all cells null)" pour éviter d'avoir des lignes blanches en pagaille si vous avez beaucoup de co-publications étant donné que les lignes qui nous intéressent sont les premières de chaque enregistrement. Une fois les paramètres d'export définis, dans l'onglet download on peut récupérer le fichier.
Gestion des affiliations dans OpenRefine
Si l'on revient dans OpenRefine on va maintenant pouvoir nettoyer les affiliations et les réorganiser pour ne conserver que ce qui nous intéresse. Je prends pour cela un exemple contenant plus de copublications sur le mien :
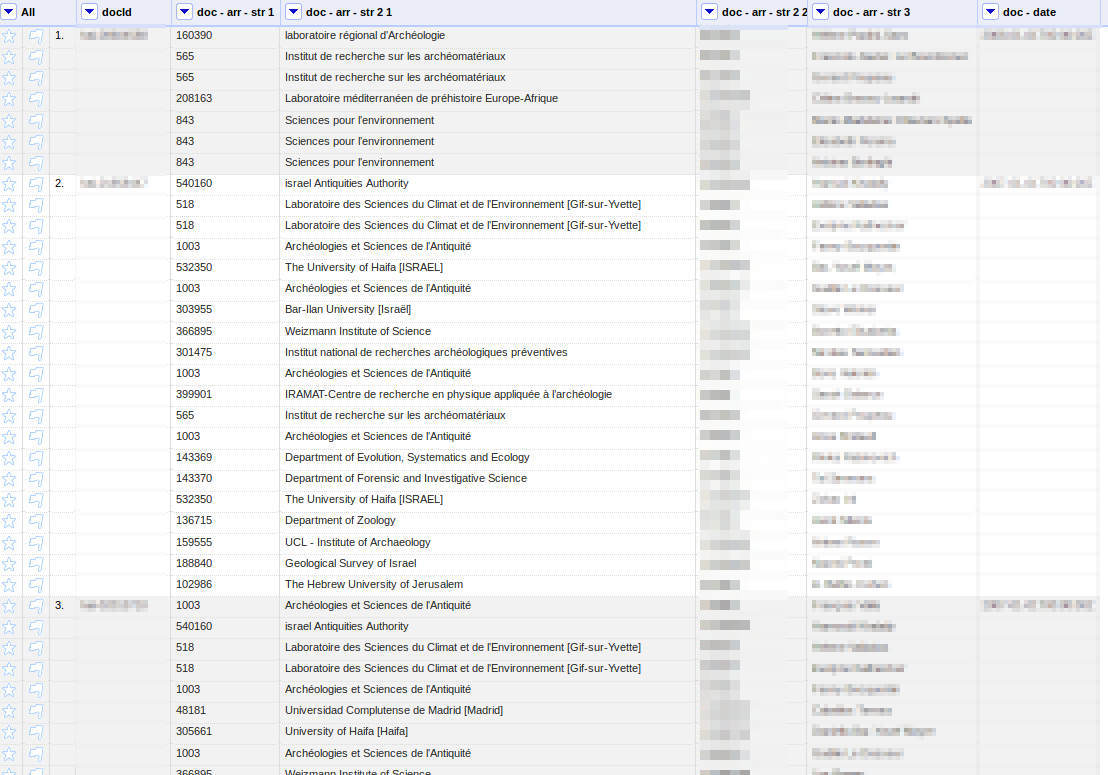
Ce qui va nous intéresser ici va être de :
- ne conserver que les affiliations de l'auteur qui nous intéresse;
- fusionner les affiliations multiples
- garder tout cela associer au docId du document pour pouvoir le réinjecter dans le fichier LibreOffice.
Les étapes pour arriver à ce résultat sont les suivantes :
- répeter les informations communes sur l'ensemble des lignes. Sur la colonne contenant les dates > Flèche de fonctions > Edit cells > Fill down. On va ensuite faire pareil sur la colonne contenant les docId. Attention à bien le faire dans ce sens, car lorsque l'on va remplir les docId, OpenRefine va considérer que l'on a plus des enregistrements avec des copubliants mais que chaque ligne correspond à un enregistrement. Dans l'exemple de mon fichier ci-dessus, j'avais 101 enregistrements qui correspondent une fois le docId "fillé down" à 674 nouveaux enregistrements par exemple.
- on va ensuite se limiter aux lignes qui concernent notre auteur. Colonne contenant les identifiants auteur (la quatrième pour moi) > text filter, on saisit l'identifiant de notre auteur. Si on a un auteur avec plusieurs identifiants on peut les saisir sous la forme
(identifiant1|identifiant2|identifiant3)après avoir coché l'option "regular expression" sous la zone de saisie du filtre. Cette expression régulière revient à dire : "identifiant1 OU identifiant2 OU identifiant3". - dans la liste qui apparaît alors, on va choisir d'afficher sous forme de lignes plutôt que sous forme d'enregistrements ("Show as: rows") puis demander, sur la colonne docId : Edit cells > Blank down, pour nettoyer à nouveau les identifiants qui sont multiples. Une fois que cela est fait on repasse en affichage par record.
Le fichier dont on dispose ressemble alors à cela :
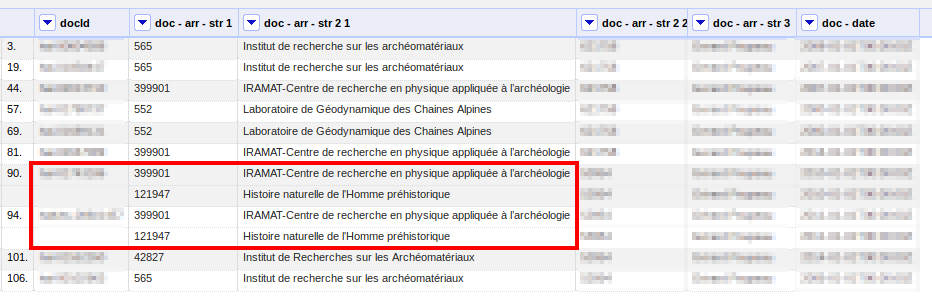
Avant de repartir vers LibreOfice, on va traiter les lignes entourées en rouge dans l'exemple ci-dessus, qui correspondent à des publications pour lesquelles l'auteur qui noue intéresse est associé à deux institutions. On va rassembler les valeurs pour un traitement plus simple dans LibreOffice. Pour cela, sur la colonne contenant les affiliations, après s'être assuré que l'on est bien en mode record, on va choisir Edit cells > Join multi-valued cells, on choisit le séparateur qui nous intéresse et on a alors un regroupement des éventuelles multi-affiliations d'un auteur.
Comme tout à l'heure, on peut maintenant faire un export à partir de cette liste (en conservant le filtre actif pour l'auteur en cours) en choisissant de n'export que les identifiants de notice HAL et la colonne contenant les affiliations regroupées.
Traitement final dans LibreOffice
Le résultat de l'export précédent va être intégré dans une nouvelle feuille du fichier LibreOffice pour pouvoir être traité. Dans l'onglet principal, on ajoutera alors une colonne contenant la formule suivante :
=SINA(RECHERCHEV(A2;$Feuil2.A$1:$Feuil2.B$98;2;0);"Aucune affiliation")Le principe de cette fonction est le suivant :
- on fait un RECHERCHEV de l'identifiant du document dans la second feuille et on affiche la valeur de la colonne 2 qui correspond à la liste des affiliations d'un chercheur pour la publi;
- si RECHERCHEV renvoie une erreur (SINA), dans le cas où une entrée était retournée par l'API mais avec des affiliations pour des coauteurs mais aucune pour l'auteur qui nous intéresse par exemple, on va se contenter d'indiquer "Aucune affiliation".
On obtient alors le fichier suivant, qui va nous permettre d'apporter les modifications nécessaires à HAL pour les affiliations qui pourraient être manquantes sur certaines publications :
